网友您好, 请在下方输入框内输入要搜索的题目:
试题四(共 15分)
阅读以下说明和C函数,将解答填入答题纸的对应栏内。
【说明】
函数del_substr(S,T)的功能是从头至尾扫描字符串 S, 删除其中与字符串T相同的所有子串,其处理过程为:首先从串 S 的第一个字符开始查找子串 T,若找到,则将后面的字符向前移动将子串T覆盖掉,然后继续查找子串T,否则从串S的第二个字符开始查找,依此类推,重复该过程,直到串S的结尾为止。该函数中字符串的存储类型 SString
定义如下:
typedef struct {
char *ch; /*串空间的首地址*/
int length; /*串长*/
}SString;
【C函数】
void del_substr(SString *S, SString T)
{
int i, j;
if ( S->length < 1 || T.length < 1 || S->length < T.length )
return;
i = 0; /* i为串S中字符的下标 */
for ( ; ; ) {
j = 0; /* j为串T中字符的下标 */
while ( i < S->length && j < T.length ) { /* 在串S中查找与T相同的子串 */
if ( S->ch[i]==T.ch[j] ) {
i++; j++;
}
else {
i = (1) ; j = 0; /* i值回退,为继续查找T做准备 */
}
}
if ( (2) ) { /* 在S中找到与T相同的子串 */
i = (3) ; /* 计算S中子串T的起始下标 */
for(k = i+T.length; k<S->length; k++) /* 通过覆盖子串T进行删除 */
S->ch[ (4) ] = S->ch[k];
S->length = (5) ; /* 更新S的长度 */
}
else break; /* 串S中不存在子串T*/
}
}
试题四参考答案
(1)i-j+1,或其等价形式 (3分)
若考生解答为i-j,则给1分
(2)j==T.length,或j>=T.length,或其等价形式 (3分)
(3)i-j (3分)
(4)k -T.length,或k-j,或其等价形式 (3分)
(5)S->length-T.length,或S->length-j (3分)
●试题五
阅读以下程序说明和C程序,将应填入(n)处的子句,写在答卷纸的对应栏内。
【程序说明】
函数int commstr(char *str1,char *str2,int *sublen)从两已知字符串str1和str2中,找出它们的所有最长的公共子串。如果最长公共子串不止1个,函数将把它们全部找出并输出。约定空串不作为公共子串。
函数将最长公共子串的长度送入由参数sublen所指的变量中,并返回字符串str1和str2的最长公共子串的个数。如果字符串str1和str2没有公共子串,约定最长公共子串的个数和最长公共子串的长度均为0。
【程序】
int strlen(char *s)
{char *t=s;
while(*++);
return t-s-1;
}
intcommstr(char)*str1,char *str2,int *sublen
{char*s1,*s2;
int count=0,len1,len2,k,j,i,p;
len1=strlen(str1);
len2=strlen(str2);
if(len1>len2)
{s1=str1;s2=str2;}
else{len2=len1;s1=str2;s2=str1;}
for(j=len2;j>0;j--)/*从可能最长子串开始寻找*
{for(k=0; (1) <=len2;k++)/*k为子串s2的开始位置*/
{for(i=0;s1[ (2) ]!='\0';i++;)/* i为子串s1的开始位置*/
{/* s1的子串与s2的子串比较*/
for(p=0;p<j)&& (3) ;p++);
if ( (4) )/*如果两子串相同*/
{for(p=0);p<j;p++}/*输出子串*/
printf("%c",s2[k+p]);
printf("\n");
count++;/* 计数增1*/
}
}
}
if (count>0)break;
*sublen=(count>0)? (5) :0;
return count;
}
●试题五
【答案】(1)k+j(2)i+j-1(3)s1[i+p]==s2[k+p](4)p==j或p>=j(5)j
【解析】略。
阅读以下技术说明和流程图,根据要求回答问题1至问题3。
[说明]
图4-8的流程图所描述的算法功能是将给定的原字符串中的所有前部空白和尾部空白都删除,但保留非空字符。例如,原字符串“ FileName ”,处理变成“File Name”。图4-9、图4-10和图4-11分别详细描述了图4-8流程图中的处理框A、B、C。
假设原字符串中的各个字符依次存放在字符数组ch的各元素ch(1)、ch(2)、…、ch(n)中,字符常量 KB表示空白字符。
图4-8所示的流程图的处理过程是:先从头开始找出该字符串中的第一个非空白字符ch(i),再从串尾开始向前找出位于最末位的非空白字符ch(j),然后将ch(i)、……、ch(j)依次送入ch(1)、ch(2)、……中。如果字符串中没有字符或全是空白字符,则输出相应的说明。
在图4-8流程图中,strlen()是取字符串长度函数。
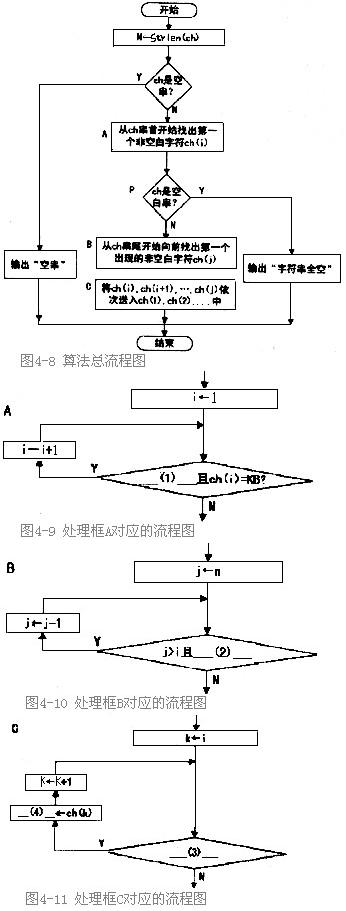
请将图4-9、图4-10和图4-11流程图中(1)~(4)空缺处的内容填写完整。
本题用分层的流程图形式描述给定的算法。图4-8所描述的流程图是顶层图,其中用A、B、C标注了 3个处理框。而图4-9、图4-10和图4—11所描述的流程图分别对这3个处理框进行了细化。 处理框A的功能是依次检查ch(1),ch(2),……(即从串首开始查找),直到找到非空白字符ch(i)。在图4-9所描述的流程图中,对i=1,2……进行循环,只要未找到字符串尾部标志(即"\0"),且ch(i)为空白字符(KB),那么还需要继续查找。因此,(1)空缺处所填写的内容是“i=n”或“n>=i”或其他等价形式。 处理框B的功能是依次检查ch(n),ch(n-1),……(即从串尾向前开始查找),直到找到非空字符ch(j)。在图4-10所描述的流程图中,对j=n,n-1……进行循环,只要ch(j)=KB(空白字符),那么还需要继续循环查找。由于B框处理的前提是A框中已经找到了非空字符ch(i),因此循环最多到达“j=i”处就会结束。可见,(2)空缺处所填写的判断条件是“ch(j)=KB”。而图4-10中的判断条件“j>i”是可有可无的。 处理框C的功能是将ch(i),ch(i+1)…,ch(j)的内容依次送入ch(1),ch(2)……中。在图4-11所描述的流程图中,对kf=i,i+l,…,j进行循环,只要满足“k=j”的条件,就要继续循并环做传送处理,因此(3)空缺处所填写的内容是“k=i”或其等价形式。 由于ch(i)应送往ch(1),ch(i+1)应送往ch(2)……,因此,ch(k)应送往ch(k-i+1)。这是程序员应熟练掌握的基本功,即从几个特例,寻找普遍规律,再用特例代进去试验是否正确。因此,(4)空缺处所填写的内容是“ch(k-i+1)”。
阅读以下说明和流程图,填补流程图中的空缺(1)~(5),将解答填入对应栏内。
【说明】
下面流程图的功能是:在已知字符串A中查找特定字符串B,如果存在,则输出B串首字符在A串中的位置,否则输出-1。设串A由n个字符A(0),A(1),…,A(n-1)组成,串B由m个字符B(0),B(1),…,B(m-1)组成,其中n≥m>0。在串A中查找串 B的基本算法如下:从串A的首字符A(0)开始,取子串A(0)A(1)…A(m-1)与串B比较;若不同,则再取子串A(1)A(2)…A(m)与串B比较,依次类推。
例如,字符串“CABBRFFD”中存在字符子串“BRF”(输出3),不存在字符子串“RFD”(输出-1)。
在流程图中,i用于访问串A中的字符(i=0,1,…,n-1),j用于访问串B中的字符(j=0,1,…,m-1)。在比较A(i)A(i/1)…A(i+m-1)与B(0)B(1)…B(m-1)时,需要对 A(i)与B(0)、A(i+1)与B(1)、…、A(i+j)与B(j)等逐对字符进行比较。若发现不同,则需要取下一个子串进行比较,依此类推。
【流程图】

(1) j+1 (2) i+1 (3) 0 (4) i (5) -1 解析:本题采用的是最简单的字符子串查找算法。
在串A中查找是否含有串B,通常是在串A中从左到右取逐个子串与串B进行比较。在比较子串时,需要从左到右逐个字符进行比较。
题中已设串A的长度为n,存储数组为A,动态指针标记为i;串B的长度为m,存储数组为B,动态指针标记为j。
如果用伪代码来描述这种算法的核心思想,则可以用以下的两重循环来说明。
外循环为:
Fori=0ton-mdo
A(i)A(i+1)...A(i+m-1)~B(0)B(1)...B(m-1)
要实现上述比较,可以采用内循环:
Forj=0tom-1do
A(i+j)~B(j)
将这两重循环合并在一起就是:
Fori = 0ton-1do
Forj = 0tom-1do
A(i+j)~B(j)
这两重循环都有一个特点:若发现比较的结果不相同时,就立即退出循环。因此,本题中的流程图可以间接使用循环概念。
初始时,i与j都赋值0,做比较A(i+j)~B(j)。
若发现相等,则继续内循环(走图的左侧),j应该增1,继续比较,直到j=m为止,表示找到了子串(应输出子串的起始位置i);若发现不等,则退出内循环,继续开始外循环(走图的右侧),j应恢复为0,i应增1,继续比较,直到i>n-m为止,表示不存在这样的子串(输出-1)。
在设计流程图时,主要的难点是确定循环的边界(何时开始,何时结束)。当难以确定边界值变量的正确性时,可以用具体的数值之例来验证。这是程序员应具备的基本素质。
阅读以下说明和流程图,回答问题1~2,将解答填入对应的解答栏内。
[说明]
下面的流程图描述了计算自然数1到N(N≥1)之和的过程。
[流程图]
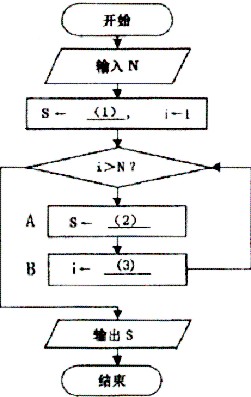
[问题1] 将流程图中的(1)~(3)处补充完整。
[问题2] 为使流程图能计算并输出1*3+2*4+…+N*(N+2)的值,A框内应填写(4);为使流程图能计算并输出不大于N的全体奇数之和,B框内应填写(5)。
(1) 0 (2) S+i (3) i+1 (4) S←S+i*(i+2) (5) i←i+2 解析:本题中,变量i用作循环变量,变量S则用于存放累加和,起初始值为0。在计算1+2+…+N时,每循环一次,将i的值累加到当前的S中,并且i自增1。为计算1*3+2*4+…+N*(N+2)的值,只需将其第i项的值i*(i+2)累加到S中;为计算不大于N的全体奇数之和,令循环变量的步长为2即可。
近3上半年程序员考试专项习题训练3及答案-下午卷试题一(共15分)阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。【说明】下面流程图的功能是:在给定的两个字符串中查找最长的公共子串,输出该公共子串的长度L及其在各字符串中的起始位置(L=0时不存在公共字串)。例如,字符串the light is not bright tonight ” 与“ Tonight the light is not bright ”的最长公共子串为 the light is not bright?,长度为22,起始位置分别为2和10。设A1:M表示由M个字符A1,A2,,AM依次组成的字符串;B1:N表示由N个字符B1, B2,,BN依次组成的字符串,MN1。本流程图采用的算法是:从最大可能的公共子串长度值开始逐步递减,在A、B字符串中查找是否存在长度为L的公共子串,即在A、B字符串中分别顺序取出长度为L 的子串后,调用过程判断两个长度为L的指定字符串是否完全相同(该过程的流程略)。【流程图】(1) N 或 min(M,N) (2) M-L+1 (3) N-L+1 (4) L-1 (5) L, I, J本题考查对算法流程图的理解和绘制能力。这是程序员必须具有的技能。本题的算法可用来检查某论文是否有大段抄袭了另一论文“the light is not bright tonight是著名的英语绕口令,它与onight the light is not bright大同小异。由于字符串A和B的长度分别为M和N,而且MN1,所以它们的公共子串长度 L必然小于或等于N。题中采用的算法是,从最大可能的公共子串长度值L开始逐步递减,在A、B字符串中查找是否存在长度为L的公共子串。因此初始时,应将min (M, N)送L。或直接将N送L。(1)处应填写N或min(M,N),或其他等价形式。对每个可能的L值,为查看A、B串中是否存在长度为L的公共子串,显然需要执行双重循环。A串中,长度为L的子串起始下标可以从1开始直到M-L+1 (可以用实例来检查其正确性);B串中,长度为L的子串起始下标可以从1开始直到N-L+1。因此双重循环的始值和终值就可以这样确定,即(2)处应填M-L+1,或等价形式;(3)处应填N-L+1或等价形式(注意循环的终值应是最右端子串的下标起始值)。A串中从下标I开始长度为L的子串可以描述为AI:I+L-1; B串中从下标J开始长度为L的子串可以描述为AJ:J+L-1。因此,双重循环体内,需要比较这两个子串(题中采用调用专门的函数过程或子程序来实现)。如果这两个子串比较的结果相同,那么就己经发现了 A、B串中最大长度为L的公共子串,此时,应该输出公共子串的长度值L、在A串中的起始下标I、在B串中的起 始下标J。因此,(5)处应填L, I, J (可不计顺序)。如果这两个子串比较的结果不匹配,那么就需要继续执行循环。如果直到循环结束仍然没有发现匹配子串时,就需要将L减少1 (4)处填L-1或其等价形式)。只要L非0,则还可以继续对新的L值执行双重循环。如果直到L=0,仍没有发现子串匹配,则表示A、B两串没有公共子串。试题二(共15分)阅读以下说明和C函数,填补函数代码中的空缺,将解答填入答题纸的对应栏内, 【说明1】函数f(double eps)的功能是:利用公式计算并返回的近似值。【函数1】【说明2】函数fun(Char *str)的功能是:自左至右顺序取出非空字符串str中的数字字符,形成一个十进制整数(最多8位)。例如,若str中的字符串为iyt?67kpf3g8d5.j4ia2e3p12”, 则函数返回值为67385423。【C函数2】(1)n+2 (2) -s 或-1*s (3) *p!=0或等价形式(4)num* 10或等价形式 (5) p+或等价形式本题考查c语言程序设计基本技能。考生需认真阅读题目中的说明,从而确定代码的运算逻辑,在阅读代码时,还需注意各变量的作用。函数f(double eps)的功能是计算的近似值。观察题中给出的计算公式,可知在循环中n每次递增2,因此空(1)处应填入n+2。由于公式中的各项是正负交替的,因此结合表达式term = S/n可知变量s就是起此作用的。空(2)处应填入-s或-1*s。对于函数fun(char *str),从字符序列中取出数字并组合为一个整数时,对于每个数字,只需将之前获取的部分乘以10再加上该数字的值即可。以67385423为例。67385423 = (0+6)* 10+7)* 10+3)* 10+8)* 10+5)* 10+4)* 10+2)* 10+3函数中的变量i是用来计算位数的,num用来计算所获得的整数值。显然,最多读取字符序列中的前8个数字,或者到达字符序列的末尾(*p!=0)时,计算也需结束。 因此,空(3)处应填入“*p!=0”。根据num的作用,空(4)处应填入“num* 10”。根据指针P的作用,空(5)处的代码应使得p指向下一个字符,因此应填入“ p+”。试题三(共15分)阅读以下说明和C代码,填补代码中的空缺,将解答填入答题纸的对应栏内。【说明】下面的程序代码根据某单位职工的月工资数据文件(名称为Salary.dat,文本文件), 通过调用函数GetlncomeTax计算出每位职工每月需缴纳的个人所得税额并以文件(名称为IncomeTax.dat,文本文件)方式保存。例如,有4个职工工资数据的Salary.dat内容如下,其中第一列为工号(整数),第2列为月工资(实数)。1030001 6200.001030002 5800.002010001 8500.002010010 8000.00相应地,计算所得IncomeTax.dat的内容如下所示,其中第3列为个人所得税额:1030001 6200.00 47.201030002 5800.00 35.942010001 8500.00 233.502010010 8000.00 193.00针对工资薪金收入的个人所得税计算公式为:个人所得税额=应纳税所得额X税率速算扣除数 其中,应纳税所得额=月工资三险一金起征点 税率和速算扣除数分别与不同的应,如表3-1所示。设三险一金为月工资的19%,起征点为3500元。例如,某人月工资为5800元,按规定19%缴纳三险一金,那么:其应纳税所得额X=58005800x19%3500=1198元,对应税率和速算扣除数分别为3%和0元,因此,其个人所得税额为1198X3%-0=35.94元。 【C代码】(1)double GetIncomeTax(double salary)或 double GetlncomeTax(double)(2)!fin或 fin=NULL 或 fin=0(3)!fout 或 fout=NULL 或 fout=0(4)&id, &salary(5)GetlncomeTax(salary)(6)salary *(1-RATE)或等价形式 注:RATE可替换为0.19本题考查c语言程序设计基本技能。考生需认真阅读题目中的说明,以便理解问题并确定代码的运算逻辑,在阅读代码时,还需注意各变量的作用。根据注释,空(1)处应填入double GetIncomeTax(double salary)或double GetlncomeTax(double)”,对函数GetlncomeTax 进行声明。空(2)、(3)处所在的代码是判断文件打开操作是否成功,因此应分别填入“!fin”、“! fout”。根据说明可知,变量id和salary分别表示工号和月工资数。空(4)处所在语句为从文件中读取数据的操作,从fscanf的格式控制串可知读取的两个数是整数和双精度浮点数,则输入表列的两个变量分别为接收整数值的变量id和接收整数值的变量salary,因此空(4)应填入“&id, &salary”。空(5)处所在代码向fout关联的文件写入计算出的所得税额,显然需调用函数GetlncomeTax 来计算,因此应填入 “ GetlncomeTax(salary) ”。空(6)处的代码计算应纳税所得额,根据说明中给出的计算公式及三险一金的计算方法:应纳税所得额=月工资三险一金起征点 空(6)处应填入“salary *(1-RATE)”。试题四(共15分)阅读以下说明和C函数,填补代码中的空缺,将解答填入答题纸的对应栏内。【说明】函数Combine(LinkList La, LinkList Lb)的功能是:将元素呈递减排列的两个含头结点单链表合并为元素值呈递增(或非递减)方式排列的单链表,并返回合并所得单链表的头指针。例如,元素递减排列的单链表La和Lb如图4-1所示,合并所得的单链表如图4-2所示。 【c函数】(1) LinkList (2) pa & pb (3) tp-next(4) tp (5) tp = pa本题考查数据结构应用及C语言实现。链表运算是C程序设计题中常见的考点,需熟练掌握。考生需认真阅读题目中的说朋,以便理解问题并确定代码的运算逻辑,在阅读代码时,还需注意各变量的作用。根据注释,空(1)所在的代码定义指向链表中结点的指针变量,结合链表结点类型的定义,应填入“LinkList ”。由于pa指向La链表的元素结点、pb指向Lb链表的元素结点,空(2)所在的while语句中,是将pa指向结点的数据与pb所指向结点的数据进行比较,因此空(2)处应填 入 pa & pb ,以使运算pa-datapb-data?中的pa和pb为非空指针。从空(3)所在语句的注释可知,需将tp所指结点插入Lc链表的头结点之后,空(3) 处应填入tp-next,空(4)处应填入tp,如下图所示。空(5)所在的while语句处理还有剩余结点的链表,pa是保存指针的临时变量循环中的下面4条语句执行后的链表状态如下图所示。空(5)处应填入“ tp = pa”,以继续上述的重复处理过程。 试题五(共15分)阅读下列说明和C+代码,填补代码中的空缺,将解答填入答题纸的对应栏内。【说明】设计RGB方式表示颜色的调色板,进行绘图,其类图如图5-1所示9该程序的C+ 代码附后。【C+代码】(1) free(palette) (2) this-number (3) static const(4) new MyColor (5) new Drawing()本题考查C+程序设计的能力,涉及类、对象、方法定义和相关操作、要求考生根据给出的案例和代码说明,认真阅读并理清程序思路,然后完成题目。先考查题目说明。本题目中涉及到颜色、调色板、绘图等类以及初始化和调色相关等操作。根据说明进行设计。类图中给出三个类Drawing、Palette和MyColor及其之间的关系。Drawing与Palette、MyColor之间具有关联关系,Palette与MyColor之间是聚合关系。MyColor为以RGB方式表不颜色,由属性red、green和blue表示,每个MyColor对象即为一个RGB颜色。MyColor具有两个构造器,缺省构造器将RGB颜色均初始化为0;带参数的构造方法将当前对象的RGB值设置为调用构造方法时消息中所传递的参数值。pr
阅读以下说明和流程图,填补流程图中的空缺(1)一(5),将解答填入答题纸的对应栏内。
【说明】
下面的流程图采用公式ex=1+x+x2/2 1+x3/3 1+x4/4 1+…+xn/n!+???计算ex的近似值。设x位于区间(0,1),该流程图的算法要点是逐步累积计算每项xx/n!的值(作为T),再逐步累加T值得到所需的结果s。当T值小于10-5时,结束计算。
【流程图】
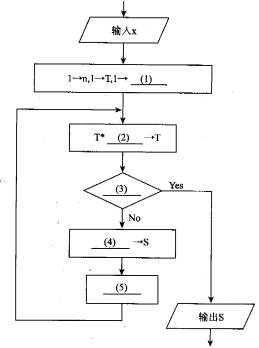
(1)S (2)x/n (3)T<O.00001 (4)S+T (5)n+1->n 解析:在题目中已经给出了指数函数ex的公式,即基本算法,另外也给出了计算过程中控制误差终止计算的方法。本题主要的重点是如何设计计算流程,实现级数前若干项的求和,以及判断计算终止的条件。级数求和一般都是采用逐项累加的方法。从流程图我们可以看出s为累加结果,T为动态的项值,最后通过s+T->S来完成各项的累加。已知T=xnx/n!,如果每次都直接计算T的值,计算量会比较大。从ex的公式中我们可以看出每一项都一个共同点,就是后一项和前一项有简单的关系Tn=T(n-i)*x/n,我们可以充分利用前项的计算结果来计算后一项,这样就会大大减少计算量。这也是程序员需要掌握的基本技巧。在流程图中,一开始先输入变量x,接着对其他变量赋初值。级数项号n的初始值为1,逐次进行累积的T的初始值为1,根据后面的流程推断可以看出逐次进行累加的s应该有初始值l的(在输入的x满足条件直接退出循环的时候根据公式输出的值为D,所以空(1)的答案为“S”。从前面分析直到e。的公式中后一项和前一项有简单的关系Tn=T(n-i)*x/n,所以空(2)的答案为“x/n”。空(3)处是判断计算过程结束的条件,按照题目中的要求“当T值小于lO-5时,结束计算。”所以空(3)的答案为“T<0.00001”。按照题意空(4)处是要对每项的结果进行累加赋给S,实现s+T->s,所以空(4)的答案为“S+T”。流程走到空(5)的时候已经求出第n项的值Tn,并累加到s中,根据算法下一步应该计算第n+1项的值,所以这里需要对级数的项号n进行自增,空(5)的答案可以为“n+=1”或者n++,但是根据流程图以上的书写风格写为“n+1->n”应该是最佳答案。
阅读以下说明和流程图,填补流程图中的空缺(1)~(5),将解答填入对应栏内。
[说明]
下面的流程图旨在统计指定关键词在某一篇文章中出现的次数。
设这篇文章由字符A(0),…,A(n-1)依次组成,指定关键词由字符B(0),…,B(m-1)依次组成,其中,n>m≥1。注意,关键词的各次出现不允许有交叉重叠。例如,在“aaaa”中只出现两次“aa”。
该流程图采用的算法是:在字符串A中,从左到右寻找与字符串B相匹配的并且没有交叉重叠的所有子串。流程图中,i为字符串A中当前正在进行比较的动态予串首字符的下标,j为字符串B的下标,k为指定关键词出现的次数。
[流程图]

0-k i+j i+m i+1 i 解析:本题考查用流程图描述算法的能力。
在文章中查找某关键词出现的次数是经常碰的问题。例如,为了给文章建立搜索关键词,确定近期的流行语,迅速定位文章的某个待修改的段落,判断文章的用词风格,甚至判断后半本书是否与前半本书是同一作者所写(用词风格是否一致)等,都采用了这种方法。
流程图最终输出的计算结果K就是文章字符串A中出现关键词字符串B的次数。显然,流程图开始时应将K赋值0,以后每找到一处出现该关键词,就执行增1操作K=K+1。
因此(1)处应填0→K。
字符串A和B的下标都是从0开始的。所以在流程图执行的开始处,需要给它们赋值0。接下来执行的第一个小循环就是判断A(i),A(i+1),…,A(i+j-1)是否完全等于B(0),B(1),…,B(m-1),其循环变量j=0,1,…,m-1。只要发现其中对应的字符有一个不相等时,该小循环就结束,不必再继续执行该循环。因此,该循环中继续执行的判断条件应该是A(i+j)=B(j)且jm。只要遇到A(i+j)≠B(j)或者j=m(关键词各字符都己判断过)就不再继续执行该循环了。因此流程图的(2)处应填州i+j。
许多考生在(2)处填i,当j增1变化后,仍然使用A(i)进行比较就不对了。因此,在检查循环程序段时应多走查一次循环。
如果(2)处整体的判断条件不成立,则该判断关键词的小循环结束。此时可能有两种情况。一是在j=0,1,…,m-1时全都成立A(i+j)=B(j)(找到了一处关键词),直到j=m时才结束小循环;二是在jm时就发现了字符不等的情况,这说明此处并不出现关键词。因此流程图中用jm来区分找到与没有找到关键词的两种情况。
对于j=m,已找到一处关键词的情况,显然应该执行k=k+1,对关键词出现次数的变量k进行增1计算。同时,为了继续进行以后的判断,应将字符串A的下标i右移m(这是因为题中假设关键词的出现不允许重叠)。因此(3)处应填写i+m,表示应该从已出现的关键词后面开始再继续进行判断。由于此时的j=m,书写i+j的答案也是正确的,但这不是程序员的好习惯,因为这不符合逻辑思维的顺势,在程序不断修改的过程中容易出错。不少考生在(3)处填写i+1,这意味着下次判断关键词将从A(i+1)开始,这就使关键词的出现有可能发生部分重叠的现象。
流程图中,对于jm的情况,表示刚才判断关键词时并非各个字符都完全相同,也就是说,刚才的判断结论是此处并没有出现关键词。即A(i)开始的子串并不是关键词。因此,下次判断关键词应该以A(i+1)开始,即(4)处应填i+1。
在下次判断关键词之前还应该判断是否全文已经判断完。最后一次小循环判断应该是对A(n-m),A(n-m+1),…,A(n-1)的判断。下标n-m来自从n-1倒数m个数。可以先试验写出A(n-m),A(n-m+1),…,A(n-1),再判断其个数是否为m。经检查,个数为(n-1)-(n-m)+1=m个,所以这是正确的。也可以用例子来检查次数是否正确。检查次数是程序员的基本功,数目的计算很容易少一个或多一个。
既然最后一次判断关键词应该是对A(n-m),A(n-m+1),…,A(n-1)的判断,即对i=n-m进行的小循环判断,所以当i>n-m时就应该停止大循环,停止再查找关键词了。
阅读以下说明和流程图,将应填入(n)处的字句写在对应栏内。
[说明]
下面的流程图用于计算一个英文句子中最长单词的长度(即单词中字母个数)MAX。假设该英文句子中只含字母、空格和句点“.”,其中句点表示结尾,空格之间连续的字母串称为单词。
[流程图]
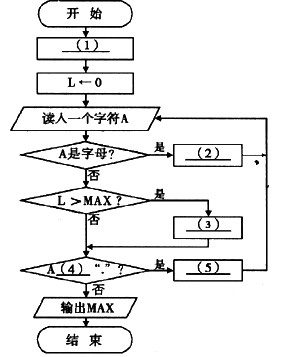
(1)MAX←0 (2)←L+1 (3)MAX←L (4)≠ (5)L←0 解析:本题用到的三个变量及其作用分别为:A,存放输入的一个字符;MAX,存放当前为止最长单词的长度;L,存放当前单同的长度。
(1)使用变量MAX应先赋予初值,由上下文知其初值为0;
(2)读取当前单词时,每读人一个字母,单词长度值L应增1;
(3)当前单词长度L比MAX时,应更新MAX的值;
(4)若当前字符不是句点,应当继续读取字符;
(5)读取下一个单词前,应当重置L的值。
阅读下列说明和流程图,将应填入(n)处。
[流程图说明]
流程图1-1描述了一个算法,该算法将给定的原字符串中的所有前导空白和尾部空白都删除,但保留非空字符之间的空白。例如,原字符串“ File Name ”,处理后变成“File Name”。流程图1-2、流程图1-3、流程图1-4分别详细描述了流程图1-1中的框A,B,C。
假设原字符串中的各个字符依次存放在字符数组ch的各元素ch(1),ch(2),…,ch(n)中,字符常量KB表示空白字符。
流程图1-1的处理过程是:先从头开始找出该字符串中的第一个非空白字符ch(i),再从串尾开始向前找出位于最末位的非空白字符ch(j),然后将ch(i),…,ch(j)依次送入 ch(1),ch(2),…中。如果原字符串中没有字符或全是空白字符,则输出相应的说明。在流程图中,strlen是取字符串长度函数。
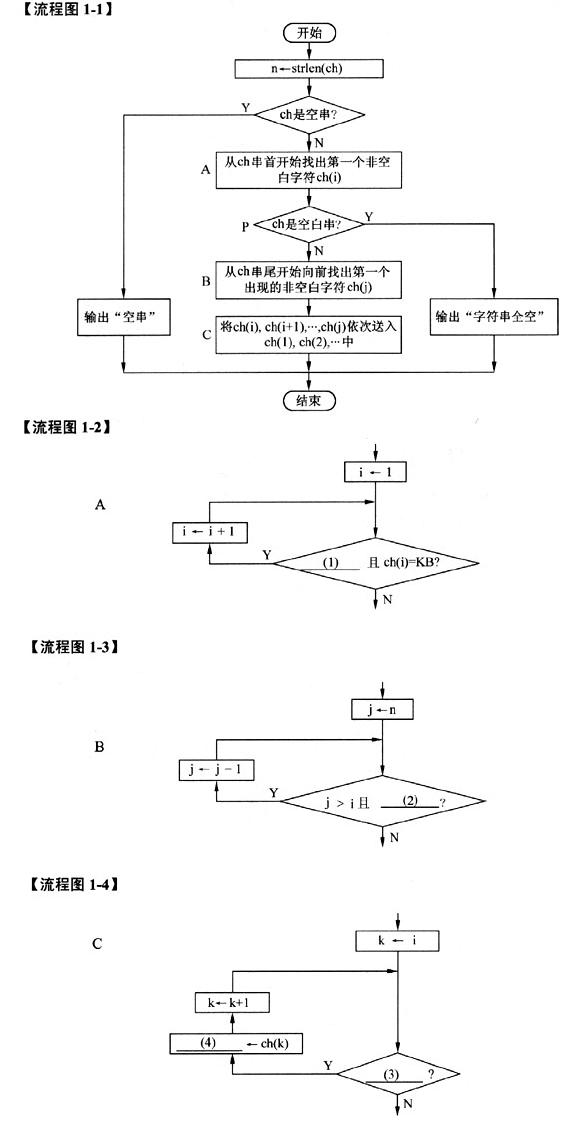
[问题]在流程图1-1中,判断框P中的条件可表示为:
i>(5)
(1) i=n, 或其等价形式 (2) ch(j)=KB (3) k=j, 或其等价形式 (4) ch(k-i+1) (5) n 解析:本题用分层的流程图形式描述给定的算法。流程图1-1是顶层图,其中用A、B、C标注了三个处理框。而流程图1-2、图1-3、图1-4分别对这三个处理框进行了细化。
A框的功能是依次检查ch(1),ch(2),…,直到找到非空白字符ch(i)。流程图1-2中,对i=1,2,…进行循环,只要尚未找到尾,而且ch(i)=KB,则还需要继续查找。因此,(1)处可填写i=n (n>=i是其等价形式)。
B框的功能是依次检查ch(n),ch(n-1),…,直到找到非空字符ch(j)。流程图1-3中,对 j=n,n-1,…进行循环,只要ch(j)=KB,则还需要继续循环查找。由于B框处理的前提是A框中已经找到了非空字符ch(i),所以,循环最多到达j=i处就会结束。因此(2)处应填写判断条件ch(j)=KB。判断条件j>i是可有可无的。
C框的功能是将ch(i),ch(i+1),…,ch(j)的内容依次送入ch(1),ch(2),…中。流程图1-4中,对k=i,i+l,…,j进行循环,即只要k=j,就要继续做传送,继续循环。因此(3)处可填写k=j。
由于ch(i)应送往ch(1),ch(i+1)应送往ch(2),…,所以,ch(k)应送往ch(k-i+1)。这是程序员应熟练掌握的基本功:从几个特例,寻找普遍规律,再用特例代进去试验是否正确。因此,(4)处应填写ch(k-i+1)。
在流程图1-1中,判断ch是空白字符串,等价于A框处理结束后没有找到空白字符。从流程图1-2中可以看出,循环变量i超过n(或达到n+1)时,就说明从头到尾都找过了,仍没有找到空白字符。因此,(5)处可以填写n。
阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。 【说明】 下面流程图的功能是:在给定的一个整数序列中查找最长的连续递增子序列。设序列存放在数组 A[1:n](n≥2)中,要求寻找最长递增子序列 A[K: K+L-1] (即A[K]<A[K+1]<…<A[K+L-1])。流程图中,用 Kj 和Lj 分别表示动态子序列的起始下标和长度,最后输出最长递增子序列的起始下标 K 和长度 L。 例如,对于序列 A={1 ,2,4,4 ,5,6,8,9,4,5,8},将输出K=4, L=5。
【流程图】 注:循环开始框内应给出循环控制变量的初值和终值,默认递增值为1,格式为: 循环控制变量=初值,终值
注:循环开始框内应给出循环控制变量的初值和终值,默认递增值为1,格式为: 循环控制变量=初值,终值
(2)Lj+1→Lj
(3)Lj > L
(4)Kj
(5)i+1
更多 “近年程序员考试考练题训练及答案(2)(测练习题)” 相关考题
- 海德格尔认为,真理的事业有哪四个领域?()A、艺术、哲学、宗教、文学B、艺术、哲学、宗教、政治C、艺术、文学、数学、哲学D、艺术、教育、哲学、宗教
- 在西方美学史上,艺术一直是美学研究的中心课题,特别是()的美学,明确地把艺术美列为主要对象。A、康德B、费希特C、黑格尔D、谢林
- 102J润滑油压力低于()报警,辐油泵启动。A、0.085MpAB、0.055MpAC、0.049MpAD、0.045MpA
- 康德认为人类心理的三个层面是感性、知性和理性。
- 治安行政许可
- 治安管理强调预防为主,是指治安管理的基本措施、方法应具有预见性、先发性,围绕防范违法犯罪和治安事故展开。
- 我们从希腊人性格中看到的三个特征,正是造成()的心灵和聪明的特征。首先是感觉的精细,善于捕捉微妙的区别。A、科学家B、艺术家C、哲学家D、统治者
- 改变认知属于情绪集中性应对。()
- 严密制度,强化暂住登记包括()A、住宿在旅店的,强化化旅店住宿登记,及时查验B、其他暂住在旅店之外的,及时进行暂住户口登记,人走注销C、港澳同胞暂住居民家中的,由暂住地户主或本人于3日内申报暂住户口登记D、正在两劳的人员,因病、因事请假回家暂住的,凭劳改、劳教机关的证明,由户主当日申报登记
- 1106L是空气过滤器。
- 2021-2022学年外研版(三起)英语三年级下册Module3单元测试卷(含答案)-
- 2021-2022学年山东省鲁科版(五四学制)(三起)五年级上册期末模拟测试英语试卷(附答案)-
- 2021-2022学年部编版道德与法治四年级下册第三单元《美好生活哪里来》单元提升题(附答案)-
- 2021-2022学年部编版道德与法治六年级下册第三单元多样文明多彩生活测试卷(附答案)-
- 部编版2021-2022学年四年级语文上学期期末课外阅读题【期末复习】(含答案)-
- 最新电大《会议策划与组织》形考作业任务01-08网考试题及答案_
- 湖南省五市十校教研教改共同体2020-2021学年高一下学期期末语文试题-
- 2013微软实习生笔试题-
- 人教PEP版三年级英语上册期中检测卷及答案-
- 人教PEP版三年级英语上册第三单元检测卷及答案-