网友您好, 请在下方输入框内输入要搜索的题目:
A、指定关键词之间的关系
B、指定检索的文档格式
C、限定关键词的位置
D、指定文档的学科类别
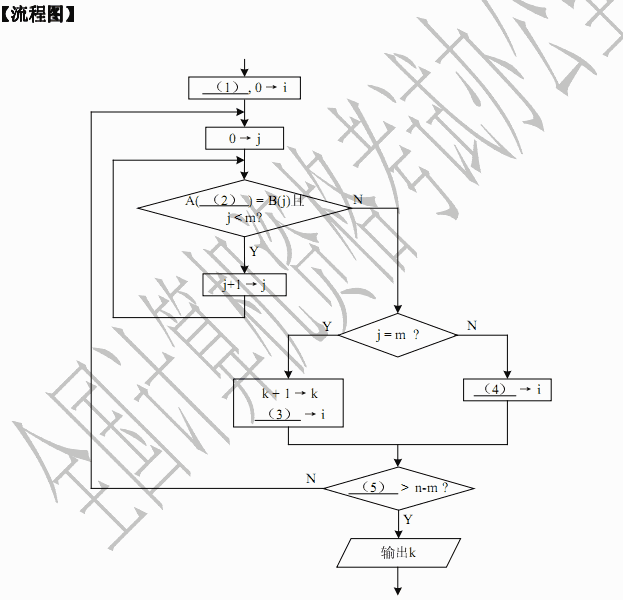
阅读以下说明和流程图,填补流程图中的空缺(1)~(5),将解答填入对应栏内。
【说明】
下面流程图的功能是:在已知字符串A中查找特定字符串B,如果存在,则输出B串首字符在A串中的位置,否则输出-1。设串A由n个字符A(0),A(1),…,A(n-1)组成,串B由m个字符B(0),B(1),…,B(m-1)组成,其中n≥m>0。在串A中查找串 B的基本算法如下:从串A的首字符A(0)开始,取子串A(0)A(1)…A(m-1)与串B比较;若不同,则再取子串A(1)A(2)…A(m)与串B比较,依次类推。
例如,字符串“CABBRFFD”中存在字符子串“BRF”(输出3),不存在字符子串“RFD”(输出-1)。
在流程图中,i用于访问串A中的字符(i=0,1,…,n-1),j用于访问串B中的字符(j=0,1,…,m-1)。在比较A(i)A(i/1)…A(i+m-1)与B(0)B(1)…B(m-1)时,需要对 A(i)与B(0)、A(i+1)与B(1)、…、A(i+j)与B(j)等逐对字符进行比较。若发现不同,则需要取下一个子串进行比较,依此类推。
【流程图】

(1) j+1 (2) i+1 (3) 0 (4) i (5) -1 解析:本题采用的是最简单的字符子串查找算法。
在串A中查找是否含有串B,通常是在串A中从左到右取逐个子串与串B进行比较。在比较子串时,需要从左到右逐个字符进行比较。
题中已设串A的长度为n,存储数组为A,动态指针标记为i;串B的长度为m,存储数组为B,动态指针标记为j。
如果用伪代码来描述这种算法的核心思想,则可以用以下的两重循环来说明。
外循环为:
Fori=0ton-mdo
A(i)A(i+1)...A(i+m-1)~B(0)B(1)...B(m-1)
要实现上述比较,可以采用内循环:
Forj=0tom-1do
A(i+j)~B(j)
将这两重循环合并在一起就是:
Fori = 0ton-1do
Forj = 0tom-1do
A(i+j)~B(j)
这两重循环都有一个特点:若发现比较的结果不相同时,就立即退出循环。因此,本题中的流程图可以间接使用循环概念。
初始时,i与j都赋值0,做比较A(i+j)~B(j)。
若发现相等,则继续内循环(走图的左侧),j应该增1,继续比较,直到j=m为止,表示找到了子串(应输出子串的起始位置i);若发现不等,则退出内循环,继续开始外循环(走图的右侧),j应恢复为0,i应增1,继续比较,直到i>n-m为止,表示不存在这样的子串(输出-1)。
在设计流程图时,主要的难点是确定循环的边界(何时开始,何时结束)。当难以确定边界值变量的正确性时,可以用具体的数值之例来验证。这是程序员应具备的基本素质。
此题为判断题(对,错)。
一篇文章选取的关键词越多,揭示文章主题就越深,可供搜索、利用的概率就越高。( )
阅读以下说明和流程图,填补流程图中的空缺(1)~(5),将解答填入对应栏内。
[说明]
下面的流程图旨在统计指定关键词在某一篇文章中出现的次数。
设这篇文章由字符A(0),…,A(n-1)依次组成,指定关键词由字符B(0),…,B(m-1)依次组成,其中,n>m≥1。注意,关键词的各次出现不允许有交叉重叠。例如,在“aaaa”中只出现两次“aa”。
该流程图采用的算法是:在字符串A中,从左到右寻找与字符串B相匹配的并且没有交叉重叠的所有子串。流程图中,i为字符串A中当前正在进行比较的动态予串首字符的下标,j为字符串B的下标,k为指定关键词出现的次数。
[流程图]

0-k i+j i+m i+1 i 解析:本题考查用流程图描述算法的能力。
在文章中查找某关键词出现的次数是经常碰的问题。例如,为了给文章建立搜索关键词,确定近期的流行语,迅速定位文章的某个待修改的段落,判断文章的用词风格,甚至判断后半本书是否与前半本书是同一作者所写(用词风格是否一致)等,都采用了这种方法。
流程图最终输出的计算结果K就是文章字符串A中出现关键词字符串B的次数。显然,流程图开始时应将K赋值0,以后每找到一处出现该关键词,就执行增1操作K=K+1。
因此(1)处应填0→K。
字符串A和B的下标都是从0开始的。所以在流程图执行的开始处,需要给它们赋值0。接下来执行的第一个小循环就是判断A(i),A(i+1),…,A(i+j-1)是否完全等于B(0),B(1),…,B(m-1),其循环变量j=0,1,…,m-1。只要发现其中对应的字符有一个不相等时,该小循环就结束,不必再继续执行该循环。因此,该循环中继续执行的判断条件应该是A(i+j)=B(j)且jm。只要遇到A(i+j)≠B(j)或者j=m(关键词各字符都己判断过)就不再继续执行该循环了。因此流程图的(2)处应填州i+j。
许多考生在(2)处填i,当j增1变化后,仍然使用A(i)进行比较就不对了。因此,在检查循环程序段时应多走查一次循环。
如果(2)处整体的判断条件不成立,则该判断关键词的小循环结束。此时可能有两种情况。一是在j=0,1,…,m-1时全都成立A(i+j)=B(j)(找到了一处关键词),直到j=m时才结束小循环;二是在jm时就发现了字符不等的情况,这说明此处并不出现关键词。因此流程图中用jm来区分找到与没有找到关键词的两种情况。
对于j=m,已找到一处关键词的情况,显然应该执行k=k+1,对关键词出现次数的变量k进行增1计算。同时,为了继续进行以后的判断,应将字符串A的下标i右移m(这是因为题中假设关键词的出现不允许重叠)。因此(3)处应填写i+m,表示应该从已出现的关键词后面开始再继续进行判断。由于此时的j=m,书写i+j的答案也是正确的,但这不是程序员的好习惯,因为这不符合逻辑思维的顺势,在程序不断修改的过程中容易出错。不少考生在(3)处填写i+1,这意味着下次判断关键词将从A(i+1)开始,这就使关键词的出现有可能发生部分重叠的现象。
流程图中,对于jm的情况,表示刚才判断关键词时并非各个字符都完全相同,也就是说,刚才的判断结论是此处并没有出现关键词。即A(i)开始的子串并不是关键词。因此,下次判断关键词应该以A(i+1)开始,即(4)处应填i+1。
在下次判断关键词之前还应该判断是否全文已经判断完。最后一次小循环判断应该是对A(n-m),A(n-m+1),…,A(n-1)的判断。下标n-m来自从n-1倒数m个数。可以先试验写出A(n-m),A(n-m+1),…,A(n-1),再判断其个数是否为m。经检查,个数为(n-1)-(n-m)+1=m个,所以这是正确的。也可以用例子来检查次数是否正确。检查次数是程序员的基本功,数目的计算很容易少一个或多一个。
既然最后一次判断关键词应该是对A(n-m),A(n-m+1),…,A(n-1)的判断,即对i=n-m进行的小循环判断,所以当i>n-m时就应该停止大循环,停止再查找关键词了。
温故而知新,下笔如有神近三上半年程序员考试专项试题训练及答案-下午卷试题一【说明】下面的流程图旨在统计指定关键词在某一篇文章中出现的次数。设这篇文章由字符A(0),A(n-l)依次组成,指定关键词由字符B(0),B(m-l) 依次组成,其中nm=l。注意,关键词的各次出现不允许有交叉重叠。例如,在“aaaa” 中只出现两次“aa”。该流程图采用的算法是:在字符串A中,从左到右寻找与字符串B相匹配的并且没有交叉重叠的所有子串。流程图中,i为字符串A中当前正在进行比较的动态子串首字符的下标,j为字符串B的下标,k为指定关键词出现的次数。 【流程图】(1) 0k (2) i+j (3) i+m (4) i+1 (5) i本题考查用流程图描述算法的能力。 在文章中查找某关键词出现的次数是经常碰的问题。例如,为了给文章建立搜索关键词,确定近期的流行语,迅速定位文章的某个待修改的段落,判断文章的用词风格,甚至判断后半本书是否与前半本书是同一作者所写(用词风格是否一致)等,都采用了这种方法。流程图最终输出的计算结果就是文章字符串A中出现关键词字符串B的次数。显然,流程图开始时应将赋值0,以后每找到一处出现该关键词,就执行增1操作k=k+1. 因此(1)处应填0K。字符串A和B的下标都是从0开始的。所以在流程图执行的开始处,需要给它们赋值0。接下来执行的第一个小循环就是判断A(i),A(i+l),A(i+j-1)是否完全等于B(0),B(1),B(m-l),其循环变量j=0,1,m-1。只要发现其中对应的字符有一个不相等时,该小循环就结束,不必再继续执行该循环。因此,该循环中继续执行的判断条件应该是A(i+j)=B(j)且jm。只要遇到或者(关键词各字符都已判断过)就不再继续执行该循环了。因此流程图的(2)处应填i+j。许多考生在(2)处填i,当j增1变化后,仍然使用A(i)进行比较就不对了。因此,在检查循环程序段时应多走查一次循环。如果(2)处整体的判断条件不成立,则该判断关键词的小循环结束。此时可能有两种情况。一是在j=0,l,m-1时全都成立(找到了一处关键词),直到j=M时才结束小循环;二是在时就发现了字符不等的情况,这说明此处并不出现关键词。因此流程图中用jm来区分找到与没有找到关键词的两种情况。对于j=m,已找到一处关键词的情况,显然应该执行对关键词出现次数的变量进行增1计算。同时,为了继续进行以后的判断,应将字符串A的下标f右移m (这是因为题中假设关键词的出现不允许重叠)。因此(3)处应填写i+m,表示应该从已出现的关键词后面开始再继续进行判断。由于此时的j=m,书写i+J的答案也是正确的,但这不是程序员的好习惯,因为这不符合逻辑思维的顺势,在程序不断修改的过程中容易出错。不少考生在(3)处填写i+1,这意味着下次判断关键词将从A(i+1)开始,这就使关键词的出现有可能发生部分重叠的现象。流程图中,对于jn-m时就应该停止大循环,停止再查找关键词了。试题二阅读以下问题说明、C程序和函数,将解答填入答题纸的对应栏内。【问题1】分析下面的C程序,指出错误代码(或运行异常代码)所在的行号。【C程序】5,或 arrChar = test 7,或*P=0本题考查C程序编写和调试中常见错误的识别和改正。在C语言中,指针表示内存单元的地址,指针变量可用于存储指针类型的值,即内存单元的地址值。变量的值在程序运行过程中允许修改,而常量则不允许修改。可以令指针指向一个变量或常量,但若指针指向一个常量,则不允许通过指针修改该常量。第5行代码有错,即对数组名arrChar的赋值处理是错误的。在C语言中,数组名是表示数组空间首地址的指针常量,程序中不允许对常量赋值。第7行代码有错,在第6行中,通过p = testing使指针变量指向了一个字符串常量,此后可以再令指针p指向其他字符或字符串,但不能通过指针修改字符串常量的内容。【问题2】函数inputArr(int a, int n)的功能是输入一组整数(输入0或输入的整数个数迖到n时结束)存入数组a,并返回实际输入的整数个数。函数inputArr可以成功编译。但测试函数调用inputArr后,发现运行结果不正确。请指出错误所在的代码行号,并在不增加和删除代码行的情况下进行修改,写出修改正确后的完整代码行,使之符合上述设计意图。【C函数】该函数中出现的错误是编写C程序时的常见错误。scanf是C标准库函数中的格式化输入函数,其原型如下: .int scanf(char *format,.);使用时,第一个实参是格式控制串,之后的实参是地址1,地址2,在本题中,要求以十进制整数格式输入一个整数并存入ak,数组元素ak实质上一个整型变量,必须用“&”求得ak的地址作为实参调用scanf函数,因此,第4行出错,正确代码应为“scanf(%d,&ak);”。C程序中将相等运算符“=”误用为赋值运算符“=”也是常见的一个错误,由于“=”也是合法的运算符并且C语言中用0和非0来表示逻辑假和逻辑真,因此在应产生逻辑值的地方产生了其他数值也可以,因此该错误通常只能用人工检查和排除。第6行的正确代码应为“if(k=n)break;”。在该程序中,结束循环的一个条件是k等于n,另一个条件是输入的整数为0。另外,do-while的循环条件为真(非0)时要继续循环,因此,循环条件应该是判断输入的值不等于0。观察循环体中与数组元素有关的部分,如下所示:scanf(%d, &ak);k+;也就是说输入为0时存入了ak,而循环判断条件“ak=0”中的ak相对于刚存入了0的数组元素来说已经是ak+l了,.因此正确的条件为“ak-l!=0”。试题三【说明】基于管理的需要,每本正式出版的图书都有一个ISBN号。例如,某图书的ISBN号为“978-7-5606-2348-1”。ISBN号由13位数字组成:前三位数字代表该出版物是图书(前缀号),中间的9个数字分为三组,分别表示组号、出版者号和书名号,最后一个数字是校验码。其中,前缀号由国际EAN提供,已经采用的前缀号为978和979;组号用以区别出版者国家、地区或者语言区,其长度可为15位;出版者号为各出版者的代码,其长度与出版者的计划出书量直接相关;书名号代表该出版者该出版物的特定版次;校验码采用模10加权的算法计算得出。校验码的计算方法如下:第一步:前12位数字中的奇数位数字用1相乘,偶数位数字用3相乘(位编号从左到右依次为13到2)。第二步:将各乘积相加,求出总和5。第三步:将总和S除以10,得出余数R。第四步:将10减去余数R后即为校验码V。若相减后的数值为10,则校验码为0。 例如,对于ISBN号“978-7-5606-2348-1”,其校验码为1,计算过程为:S=9X1+7X3+8X1+7X3+5X1+6X3+0X1+6X3+2X1+3X3+4X1+8X3=139R=139mod10=9V=10-9= 1函数check(char code)用来检查保存在code中的一个ISBN号的校验码是否正确,若正确则返回true,否则返回false。例如,ISBN号“978-7-5606-2348-1”在code中的存储布局如表3-1所示(书号的各组成部分之间用分隔): (1) k+,或temp+(2) i12,或ik1( (空(1)处填k+),或i temp-1 (空(1)处填temp+),或等价形式(3) tarri*3,或*(tarr+i)*3,或等价形式(4) tarri,或*(tarr+i),或等价形式(5) S%10,或等价形式本题考查C程序设计基本技术。根据题目中的描述,在函数check(char code)中要先将保存在code中的编码存入tarr,同时根据题例中的tarr内容示例表可知,ISBN号前12位数字中的奇数位数字会存入tarr的偶数下标,偶数位数字存入tarr的奇数下标。将13位ISBN号存入tarr的代码如下所示:显然,空(1)处tarr的下标索引值不能使用i,需要另一个整型变量,题目中提供了k和temp,因此在此处用k+或temp+都可以。空(2)(4)处所在代码实现校验码的计算方法中的第一步和第二步,由于共需计算12位,因此空(2)处填入“i=0,或等价形式(2) index(3) lh=rh,或等价形式(4) key, cityTable mid或key, *(cityTable+mid)(5) mid本题考查c语言程序设计基本能力。要求考生根据给出的案例和执行过程说明,认真阅读理清程序思路,然后完成题目。本题涉及一维和二维数组操作,以及数组上的查
请补充函数proc(),该函数的功能是:删除字符数组中小于指定字符的字符,指定字符从键盘输入,结果仍保存在原数组中。 例如,输人“abcdefghij”,指定字符为“f”,则结果输出“fghij”。 注意:部分源程序给出如下。 请勿改动main()函数和其他函数中的任何内容,仅在函数proc()的横线上填入所编写的若干表达式或语句。 试题程序:
【l】i++【2】str[j++]=str[i]【3】str[j]=ˊ\0ˊ
【解析】要删除字符串中小于指定字符的字符,就要把字符串中每一个字符跟指定字符相比较,小于指定字符的字符不予处理,因此【l】处填“i++”;把大于等于指定字符的字符保存在原字符串中,因此【2】处填“str[j++]=str[i]”;处理完整个字符串后.为新生成的字符串添加结束符,因此【3】处填“str[j]=ˊ\0ˊ”。
请补充main()函数,该函数的功能是:从键盘输人一个字符串及一个指定字符,然后把这个字符及其后面的所有字符全部删除。结果仍然保存在原串中。 例如,输人“abcdefg”,指定字符为“d”,则输出“abe”。 注意:部分源程序给出如下。 请勿改动main()函数和其他函数中的任何内容,仅在main()函数的横线上填入所编写的若干表达式或语句。 试题程序:
【1】break;【2】i++【3】ˊ\0ˊ
【解析】题目要求删除指定字符后的所有字符,将字符串中的字符从第一个开始与指定字符相比较,直到找到第一个与指定字符相同的字符结束。因此,【l】处填“break;”;【2】处填“i++”;为新的字符串添加结束符,因此,【3】处填“ˊ\0ˊ”。
?????? 阅读以下说明和流程图,填补流程图中的空缺(1)~(5),将解答填入答题纸的
对应栏内。
【说明】
本流程图旨在统计一本电子书中各个关键词出现的次数。假设已经对该书从头到尾
依次分离出各个关键词{A(i)li=l,…,n}(n>1)}.其中包含了很多重复项,经下面的流程
处理后,从中挑选出所有不同的关键词共m个{K(j)[j=l,…,m},而每个关键词K(j)出现的次数为NK(j).j=l,…,m。

??????
??流程图中的第1框显然是初始化。A(1)→K(1)意味着将本书的第1个关键词作为选出的第1个关键词。1→NK(1)意味着此时该关键词的个数置为1。m是动态选出的关键词数目,此时应该为1,因此(1)处应填1。?本题的算法是对每个关键词与已选出的关键词进行逐个比较。凡是遇到相同的,相??应的计数就增加1;如果始终没有遇到相同关键词的,则作为新选出的关键词。流程图第2框开始对i=2,n循环,就是对书中其他关键词逐个进行处理。流程图第3框开始j=l,m循环,就是按已进出的关键词依次进行处理。接着就是将关键词A(i)与选出的关键词K(j)进行比较。因此(2)处应填K(j)。如果A(i)=K(j),则需要对计数器NK(j)增1.即执行NK(j)+1→NK(j)。因此(3)处应填NK(j)+I→NK(j)。执行后,需要跳出j循环,继续进行i循环,即根据书中的下一个关键词进行处理。如果A(i)不等于NK(j),则需要继续与下个NK(j)进行比较,即继续执行j循环。如果直到j循环结束仍没有找到匹配的关键词,则要将该A(i)作为新的已选出的关键词。因此,应执行A(i)→K(m+1)以及m+l→m。更优的做法是先将计数器m增1,再执行A(j)→K(m)。因此(4)处应填m+l→m,(5)处应填A(i)。试题一参考答案(1)1(2)K(j)(3)Nk(j)+I→NK(j)或NK(j)十十或等价表示(4)m+l→m或m++或等价表示(5)A(i)??
试题一(共15 分 )
阅读以下说明和流程图,将应填入 (n) 处的字句写在答题纸的对应栏内。
【 说明 】
下面的流程图旨在统计指定关键词在某一篇文章中出现的次数。
设这篇文章由字符A(0),…,A(n-1)依次组成,指定关键词由字符B(0),…,B(m-1)依次组成,其中n>m≥1。注意,关键词的各次出现不允许有交叉重叠。例如,在“aaaa”中只出现两次“aa”。
该流程图采用的算法是:在字符串A中,从左到右寻找与字符串B相匹配的并且没有交叉重叠的所有子串。流程图中,i 为字符串 A 中当前正在进行比较的动态子串首字符的下标,j为字符串B 的下标,k为指定关键词出现的次数。
试题一参考答案(15分)注意:此题解答中的字母不区分大小写1,0→k,或k←0,或k=0,或等价形式3分2,i+j,或等价形式3分3,i+m或i+j,或等价形式3分4,i+1,或等价形式3分5,i3分
为工作簿添加摘要信息,说明文件类别为“试题练习”,关键词为“Excel”,备注为“涵盖大纲全部内容”。
[$]
更多 “程序员考试专题测练及答案(2)(专项考练)” 相关考题
- “夫礼之初,始诸饮食”一语出自()A、《诗经》B、《礼记》C、《左传》D、《楚辞》
- 转场航空器超过预定起飞时间()仍未起飞,又未申请延期的,其原飞行申请失效。A、半小时B、一小时C、两小时
- 2009年11月,工业和信息化部计算机信息系统集成资质认证工作办公室发布《关于开展信息系统工程监理工程师资格认定有关事项的通知》(工信计资【2009】8号),要求信息系统工程监理工程师申请人所参加过的信息系统工程监理项目累计投资总值在()万元以上。A、200B、1000C、400D、500
- 烧尾宴
- 博学公司网络系统工程改造项目,建设内容包括网络工程建设、应用服务系统集成、综合布线与机房建设等,经建设单位同意及监理审查确认后,甲承建单位选择了乙承建单位作为分包单位,承担机房与综合布线建设任务。监理实施过程中,在方案设计选优、设备选型、现场旁站、工程深化设计、工程实施、工程测试、验收以及技术培训等方面实施全过程监理服务。 布线系统安装结束后监理应及时督促承建单位完成光纤和UTP的测试。请列出至少5项UTP测试项。
- 李某大学毕业后在M公司销售部门工作,后由于该公司软件开发部门人手较紧,李某被暂调到该公司软件开发部开发新产品,两个月后,李某完成了该新软件的开发。该软件产品著作权应归()所有。A、李某B、M公司C、李某和M公司D、软件开发部
- 四川风味
- 以下关于应激概念的描述哪一项是正确的()。A、常用于描述人体对施加于其上的各种要求的反应B、常用于描述人体对于紧急情况的反应C、常用于描述人体应付压力的方法
- 结构化分析方法(SA)的主要思想是()。A、自顶向下、逐步分解B、自顶向下、逐步抽象C、自底向上、逐步抽象D、自底向上、逐步分解
- 用一对吊索同时起重或悬吊时,该吊索形成的夹角度到达60度时,其负荷能力减少大约多少?()A、百分之30B、百分之50C、百分之15